Summary
I’m heading off to Austin to visit old haunts, friends, and learn a bunch about what other people are excited about and researching right now. I’ve found that trying to get a sense of what the twitterverse is talking about just from the moment-of stream can be overwhelming at times. The Twitter API is not built for retrospective analyses (it will only give you the most recent 2500 posts for a given filter, say “#evol2016”) . Instead, invest a bit of time in to setting up a Twitter stream to capture tweets relating to specific topics before a conference, and then you’ll have a much larger sample you can play around with. In R, I have found that the streamR package is really easy to use. Getting Twitter API access does not take much time and just requires clicking on some buttons, see the streamR page for insight there. Once you have your twitter corpus, tidytext is an easy way to do some easy natural language processing stuff to get you to something like a wordcloud.
Twitter and R
I was on the fence about twitter and conferences for a long awhile, but there’s a certain amount of fun in seeing what everyone is excited about and focused on. However, this can easily start to get out of hand if it is a larger conference and there are a number of people live-tweeting or whatever. I’ve found a somewhat easier way, if you actually want to dig into this information a bit more, is to set up a Twitter stream to automatically monitor the torrent of tweets coming out, and pull down any with pre-designated words/etc that you want. As I mentioned in the summary, streamR by Pablo Barbera is really easy to use.
In the leadup to Evolution 2016, I set up a script on a computer I’m not taking with me as follows:
load("my_oauth")
library(streamR)
#collecting all tweets that contain at least one of the following terms
#following Barbera et al. 2015 tweeting from left to right
# this script will be run once every hour, and tweets are stored in different
# files, whose name indicate when they were created.
current.time <- format(Sys.time(), "%Y-%m-%d-%H-%M")
f <- paste0("evol2016_", current.time, ".json")
keywords<-c('evol2016')
filterStream(file.name=f, track = keywords, timeout = 3600, oauth = my_oauth)
This script will pull down all tweets that include “evol2016” for up to an hour and dump them all into a json with the starting time tagged in the filename. There are other functions to sample up to 1% of all tweets in a semi-random fashion, but if you actually know what you want to focus on before an a event (ie being a pre-cog), this will usually suffice. And to reiterate, twitter is not very good at letting you pull down stuff easily after the fact (limits to 2500 most recent relevant posts).
These streams tend to die out, hence why it is good to restart a stream every hour or so.
#!/bin/bash
for i in {1..240}; do
Rscript collect_evol2016.R
echo $i
done
Once you have some tweets in a few jsons, there are two paths to easily analyzing them. If you’ve pulled down a large number and want to do some serious analysis, you may want to check out smappR which has some code to dump json files into a mongoDB database. However, at a conference scale that’s probably overkill so I’d recommend just merging the jsons into one large file “cat evol2016*json > merged_evol2016.json” and then using the parseTweets function provided by streamR. Here is how to do some simple processing of the tweets to remove URL links and some other trash so you can make a simple wordcloud. The sky is of course the limit at this point, you could also do some sentiment analysis stuff. Anyway, check out the intro vignette for tidytext; it is great and very easy to follow along.
library(tidytext)
library(ggplot2)
library(tm)
library(wordcloud)
library(streamR)
library(dplyr)
df<-parseTweets('merged_evol2016.json')
#not great, but seems to get rid of URLs reliably
df$text<-gsub(" ?(f|ht)(tp)(s?)(://)(.*)[.|/](.*)",'',df$text)
tidy_tw<-df %>% unnest_tokens (word,text)
tw_stop<-data.frame(word=c('rt','https','t.co','___'),lexicon='whatevs')
data("stop_words")
tidy_tw <- tidy_tw %>%
anti_join(tw_stop)
tidy_tw <- tidy_tw %>%
anti_join(stop_words)
print(tidy_tw %>% count(word, sort = TRUE))
fig<-tidy_tw %>%
count(word) %>%
with(wordcloud(word, n, max.words = 100,colors=brewer.pal(8,'Dark2')))
png('evol2016_wordcloud.png')
fig<-tidy_tw %>%
count(word) %>%
with(wordcloud(word, n, max.words = 100,colors=brewer.pal(8,'Dark2')))
dev.off()
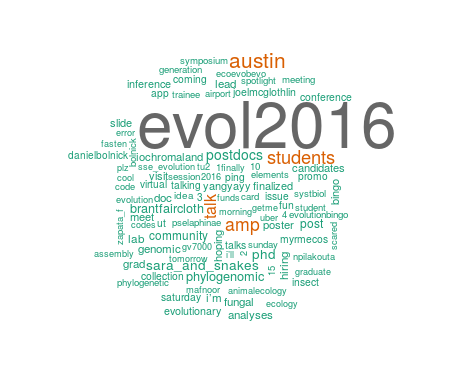
This script will then get you some approximation of the wordcloud below (words are randomly assembled so it will end up looking fairly different each time). Since I started pulling down tweets there have only been 450 posts, so there’s not a huge difference in word numbers that would be picked up by the coloring. I figure by this evening (the night before the conference actually begins) it will start picking up considerably.
Anyway, I think I’ll be able to pull some of these tweets off my home computer while I’m in Austin to give further silly wordcloud updates, but we’ll see.